
Preparing your data.
Raven's Eye can analyze natural language word data across several formats, including:
- previously saved documents containing natural language text in one of 65 languages, such as word processing files (i.e., .docx), or spreadsheet files (e.g., .csv, .xls, or .xlsx);
- directed scanning of textual information from specific webpages, or URLs; or
- pasting text directly from your computer's clipboard.
For quick analyses of natural language text (or analyses that treat your entire response set as one meaning unit), you may find the most expedient means of preparing your data to be copying it from the source and pasting it into Raven's Eye, or saving your data into a singular and undivided wordprocessing document. If your data can be accessed via URL, we also allow directed scanning of textual information from public pages of Internet websites. For most other purposes, however, most advanced researchers will want to organize their data into a spreadsheet program, and then upload it to Raven's Eye.
In this section, we discuss how to prepare your data according to these formats. We order them according to their presentation to the user as options in our online software. To facilitate your learning, you may also want to refer to our preparing your data video tutorial.
Word processing documents.
If your word processing program will save or export your textual information to .docx format, you can upload it to Raven's Eye for analysis.
In order to prepare your natural language data for uploading as a .docx word processing document, you should first clean it of inadvertent formatting, html, images, or other non-textual or non-numeric information.
After you have cleaned your data, save it in .docx format by selecting the Save As or Export feature of your word processing program. Save your document to a location on your computer from which you can upload it to Raven's Eye.
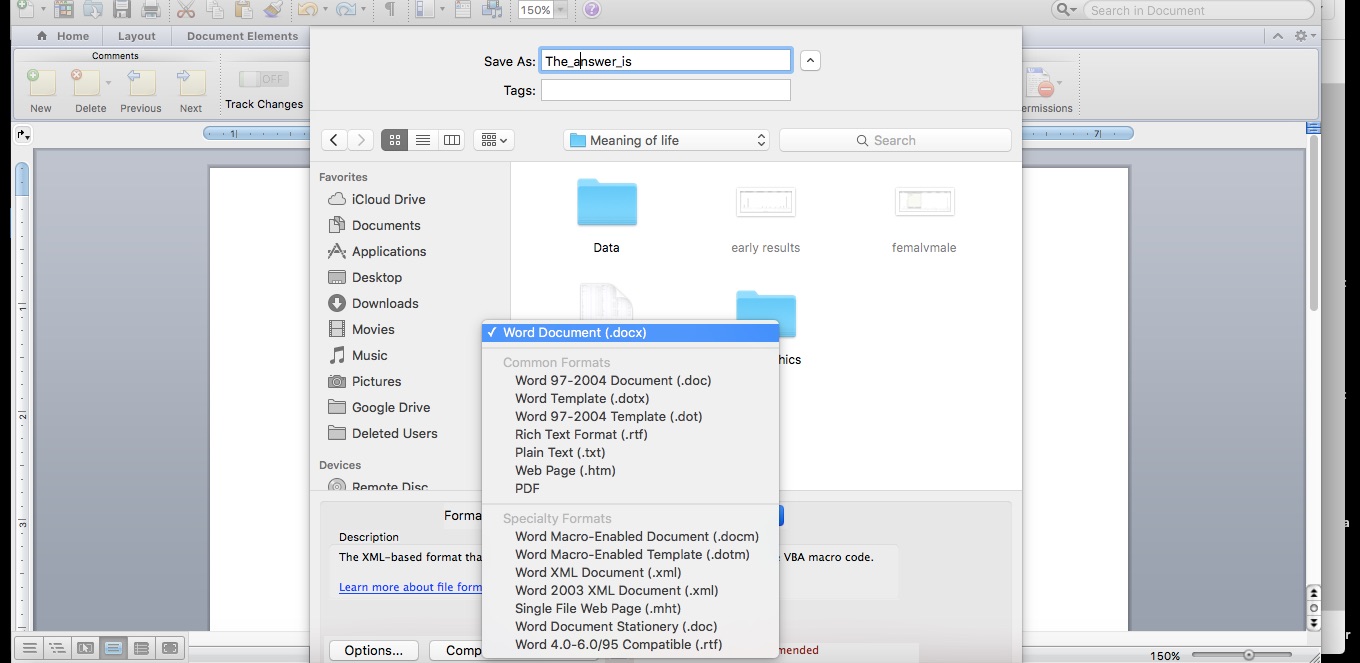
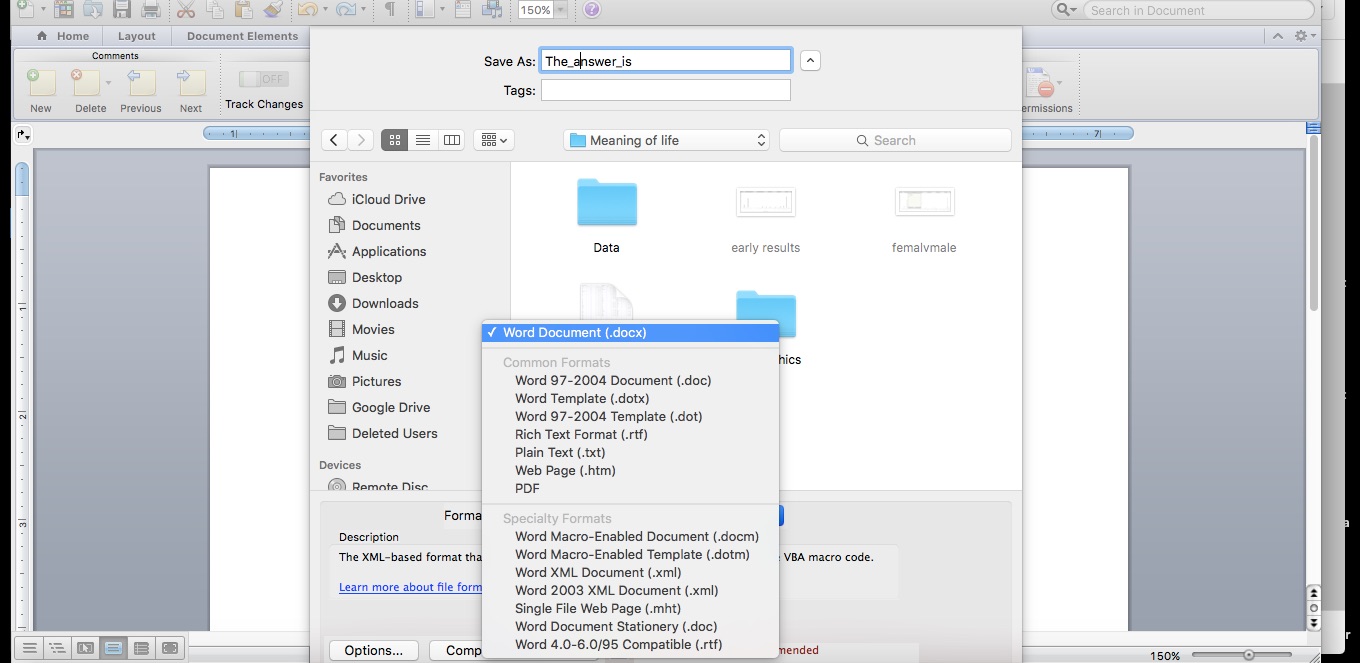
Once you have completed these steps, you are ready to log in and upload your word processing textual data for analysis.
Spreadsheets.
Raven’s Eye works on any spreadsheet saved in .csv, .xls, or .xlsx formats. Other than cleaning your data to remove formatting, character strings, images, or other non-textual or non-numeric information, there are only a few things that should be done when preparing your spreadsheet data:
- First, you will need to arrange your data so that your variables and responses are ordered by column, and your cases are ordered by rows. Each case represents a single instance of your meaning units. As such, it might take the form of one participant's responses to survey questions, a paragraph among others in chapter, an essay among others on a given topic, etc.




- Next, you will want to make sure that your column labels are accurate, and are free from spaces and punctuation. Ensure that you have labeled all columns, and that there are no spaces, and no periods, quotation marks, parentheses, or other punctuation in the labels.


- Thirdly, you will want to eliminate any empty columns. To do so, click on the empty column, and then select delete in your spreadsheet program’s dropdown menu bar.


- Next, you will need to eliminate all formulas, formats, comments, and hyperlinks from all cells. You can do so by either individually editing each column, row, or cell containing formulas or formats, or you can eliminate them all at once by selecting the small rectangle in the upper-most left-hand corner of the sheet (which should highlight the entire sheet of cells), and then clearing the cells of everything but the values. If your sheet has particularly difficult formatting to remove, some find success by selecting all of the sheet, copying it, and then using the Paste Special function of their spreadsheet program to paste only the values in a completely new sheet, workbook, or file.
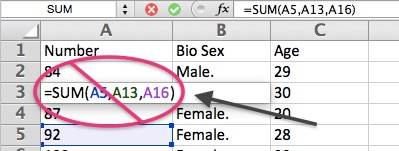
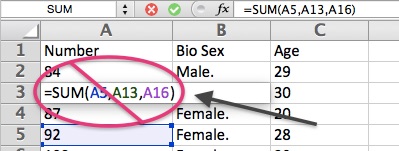
- Finally, you will need to ensure that there is only one sheet per workbook or file. If your workbook or spreadsheet file contains more than one sheet, you will need to delete all sheets but the one that contains the data that you would like to analyze. If these sheets contain information that you would like to retain, you should save the single-sheet workbook or file under a new name.


Once you have completed these steps, you are ready to log in and upload your spreadsheet textual data for analysis.
If your spreadsheet program does not normally save or export to .xls, .xlsx, or .csv file formats, check its user manual for directions on saving or exporting to these file formats prior to uploading data. Nearly all spreadsheet programs will export or save files to one or both of these file formats, though you may need to utilize a specific Export, Save As, or Share menu in your spreadsheet program to do so.
Audio files.
Automated transcription services are not available to free license holders. Attempting to transcribe audio files with a free license will result in immediate account termination and permanent ban.
Our automated transcription services provide state-of-the-art probabilistic transcription of audio files saved in .mp3, .wav, or .flac formats to our paid subscribers and institutional clients. This means that our transcription services compare your uploaded audio recording to corpora of transcribed recordings in one of nine world languages. This comparison results an a best-match transcription, which produces the text that best matches the particular fluctuations in the audio signal of your audio file. To produce the best possible transcription services for you, we partner with a world-class leader in artificial intelligence.
Though the accuracy ratings are quite good for high quality recordings (our partner's internal testing indicates a 6% error rate for recorded news casts), this process is not inerrant. To increase the accuracy of transcription, we recommend that audio files be produced from the use of high quality audio recording equipment, and that researchers employ standard industry practices during the recording of their spoken language data. For audio files containing poor quality recordings, multiple speakers, or speakers with atypical accents, we further recommend that researchers consider re-recording the audio in one speaker's voice, and then uploading this new audio file for transcription.
Because each subscriber's transcript is derived from unique circumstances beyond our or our partner's control, individual transcription results may vary substantially. To help users get the best results, each new subscription comes with 100 free minutes of transcription (even though we still incur a cost for providing them). This allows subscribers to experiment with our partner's transcription services without incurring initial additional expense.
Prior to uploading a large audio file for transcription, we recommend that subscribers use their audio editing software to isolate a 3 - 5 minute selection of their recording, and then save this as a separate audio file for use in transcription testing. After uploading and transcribing this test file, subscribers can then export their results and troubleshoot any difficulties by adjusting the recording itself (such as through reducing background noise, or adjusting the volume and reverberation, or other means determined necessary by the subscriber). This newly adjusted audio file can then be uploaded again for further testing, and this process can be repeated until the best transcription is acquired.
Transcript annotation: We proceed from a phenomenological attitude, in which preserving the voice of the speaker or writer without interpretation in the raw data is paramount (interpretation instead occurs during the analysis). Therefore, annotation about non-spoken or behavioral aspects of the interview are not automatically included in the transcript. Our partner does, however, insert an annotation into the transcript in cases where verbal fillers (such as "um," "err," etc.) or false starts (i.e., a half-spoken syllable) are present. In these instances, the word, "hesitation," is inserted into the initial transcript.
Depending on the number of such hesitations in your recording, this may affect your results, such that the apparent Overrepresentation of other words and themes is diluted. Subscribers can eliminate these annotations from their results all at once by exporting the raw data to their computer, and then using the Find and Replace All function of their spreadsheet program to identify and replace them with a space, " ". If, however, you believe that hesitations might be meaningful to the themes in the data, this information may be included as an annotation in the manner discussed in the next paragraph.
If annotation of the transcription text is desired, subscribers may do so by following our bracketing procedure in their spreadsheet programs while reviewing and editing their initial transcript (or anytime thereafter). As described in those bracketing procedures, our phenomenological perspective leads us to advocate that users insert annotations as a new column in their spreadsheet (perhaps labeled "annotation") and then assign this column as a Variable when uploading the edited transcript for analysis. In this way, each type of annotation is sortable, such that one might readily investigate whether those who hesitate—or engage in some other behavior of note—express different words or themes than those who do not (all while simultaneously preserving the original voice of the respondent).
If you believe that your audio file is of sufficient quality and is saved in one of the aforementioned formats, you may proceed to login and upload your audio file to Raven's Eye for automated transcription and analysis.
Websites or URLs.
Raven's Eye can scan and analyze text published on public websites and URLs, and can do so with very little preparation required of researchers. Indeed, all you need is the web address of the webpage that you want scanned. Once you have it, you may login and enter this web address into our site for automated analysis.
Copy and paste.
Your data can be copied to your computer's clipboard from another source and pasted directly into Raven's Eye. To prepare your data for copying and pasting into Raven's Eye, simply use the highlighting or select feature of the program that you are using to select the text that you would like to copy, and then choose that program's Copy command to copy the selected text to your computer's clipboard. If you haven't already done so, proceed to log in to Raven's Eye, and then paste your copied text into its own table for analysis.
Raven's Eye automatically removes most html and other formatting characters that may have been inadvertently captured during the copying process. However, you may occasionally capture strings of characters when copying and pasting from various sources without first cleaning your data. In some instances, the inadvertent capture of character strings may affect the apparent distribution of the words in your sample, thereby introducing various amounts of error into your results.
We recommend that users try to reduce the amount of formatting incidentally captured in the copying process by carefully selecting only the text that they are interested in analyzing, while trying to refrain from capturing clearly marked links, images, or other non-textual features that may surround that text. When general impressions are all that are required, such procedure may likely suffice in terms of data preparation. When however, precise or scientific results are required, we recommend cleaning your data such that it contains only textual or numeric data, and then uploading it via one of our supported spreadsheet formats.
Once you have copied the text that you would like analyzed, you may login to Raven's Eye and paste your text into our online software for automated analysis.
Technical considerations
Those wishing to ground their investigations in Quantitative Phenomenological methods may want to consider the information provided on the Acknowledge and refine your attitude page of our Technicals, which is first step in conducting a Quantitative Phenomenology with Raven's Eye. That step addresses several theoretical and methodological considerations that correspond with many of the practical decisions made while gathering and preparing your data.