
The meaning of life.
This report presents detailed information on the specific steps involved in conducting a quantitative phenomenology with Raven's Eye. Our presentation format has changes since this report was written. An example of our current presentation format may be found here.
Ongoing analyses.
Consider participating in our ongoing analysis of this topic by submitting your response to our ongoing survey on the meaning of life.
Initial analysis utilizing Amazon Mechanical Turk workers.
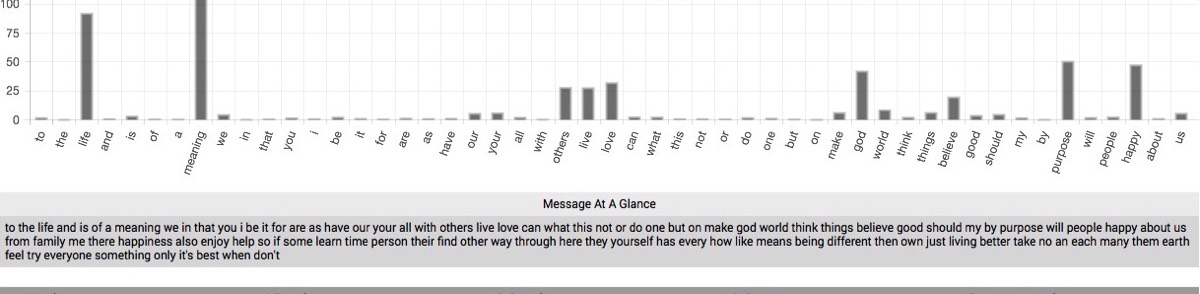
Figure 1. A screenshot of the main table chart from Question 1: …what is the meaning of life? The numbers on the y-axis indicate the degree to which a word is overrepresented in the responses. For example, in this graph, the word love is overrepresented more than 32 times its typical rate in the background corpus. All else being equal, this means that for this word to assume its background rate and become unassociated with the question, we would need to acquire 10,726 more participants (31 times our sample of 346 participants), and all of them must never mention the word love in their response to this question. Given the word’s rate of use in our current sample, this would be highly unlikely indeed.
1. Acknowledge and refine your attitude.
As we discuss in the Methods section of our Technicals, the first step in conducting a Quantitative Phenomenology with Raven’s Eye is to acknowledge and refine your attitude. This step consists of delineating the specific framework from which one is approaching the analysis of data with respect to natural language, such that the context, purpose, and boundaries of one’s research is made clear to others.
1.1 Phenomenon. We sought to understand the meaning of life, as it is understood and expressed by everyday people in various parts of the world.
1.2 Context. A number of notable individuals, groups, and academic disciplines have sought to understand the meaning of life. Indeed, there exists a deep and diverse literature of analysis and reflection on this topic. However, and perhaps due to technological limitations, projects involving the wide-scale solicitation and analysis of the thoughts and perspectives of everyday people on the matter are few and far-between.
1.3 Focus. To add to the body of literature on the meaning of life, we focus on the thoughts and perspectives of everyday people. As a practicality, in this stage, we further focus our project on a survey of Amazon Mechanical Turk workers in India and the United States (the two most proportional nationalities of such workers). In subsequent stages of our project, we will expand to include people from around the world.
1.4 Methodological approach. We conducted a Quantitative Phenomenology with Raven’s Eye. Specifically, we analyzed responses to an online survey of Amazon Mechanical Turk workers in India and the United States, which was conducted from September 15th, 2015 to September 22nd, 2015. We asked two free-response questions:
1. Over the course of a short paragraph (i.e., 3-5 sentences), please tell us in your own words: what is the meaning of life?
2. Over the course of a sentence or two, please tell us in your own words how it is that you came to your perspective on the meaning of life.
2. Over the course of a sentence or two, please tell us in your own words how it is that you came to your perspective on the meaning of life.
1.5 Variables. We solicited each participant’s age, gender, and nation, and recorded the time of submission. Participants selected their age from a dropdown menu with options ranging from 18-years-old to >100-years-old. Participants were allowed to select either Female or Male for their gender, and India or the United States as options for nation of residence. The time of submission was recorded automatically by our survey software.
1.6.1 Defining the participants. From September 15th to September 22nd, 2015, 346 participants completed our online survey through Amazon Mechanical Turk. Of the participants, 144 (41.6%) reported being Male, while 202 (58.4%) reported Female as their gender. India was selected as the nation of residence for 83 of the respondents (24.0%), while the remaining 263 respondents (76.0%) selected the United States as their nation of residence. Reported age ranged from 18-years-old to 78-years-old, with those in their 20s to 30s being represented more frequently than those in other age groups. Figures 2, 3, and 4 graphically represent the reported characteristics of our sample in terms of gender, nation of residence, and age.
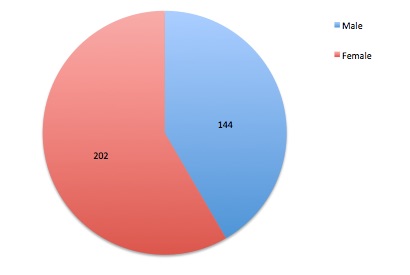
Figure 2. Reported gender of Amazon Mechanical Turk workers.
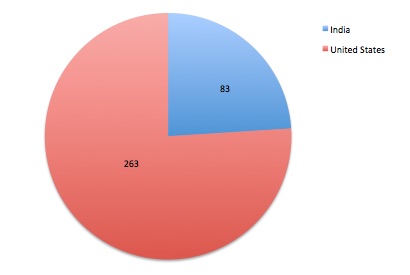
Figure 3. Reported nation of residence for Amazon Mechanical Turk workers.
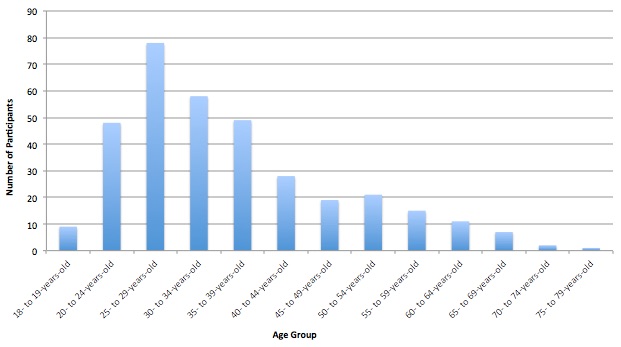
Figure 4. Distribution of reported age for Amazon Mechanical Turk workers.
1.6.2 Defining the acquired natural language pool. To define our natural language pool, we first combine all the data from all questions that elicited natural language responses. In our survey, this consisted of the two questions noted in section 1.4. The natural language pool acquired in response to both of these questions combined consisted of 29,349 words, comprising 1,962 sentences. The average sentence was, therefore, 14.95 words in length. On average, each response to a question contained 42.41 words. As a result, the typical participant used about 2.84 sentences to answer each question. The Flesch Reading Ease Score and Flesch-Kincaid Grade Level for the entire response set were 74.39 and 6.6, respectively.
Such scores indicate that overall, the participants expressed an average level of verbosity and cognitive functioning in their responses. Word counts, sentence counts, average sentence length, average response length, and Flesch scores for each separate question are analyzed in more detail in step 2.2.1.
Such scores indicate that overall, the participants expressed an average level of verbosity and cognitive functioning in their responses. Word counts, sentence counts, average sentence length, average response length, and Flesch scores for each separate question are analyzed in more detail in step 2.2.1.
2. Get a sense of the whole.
The second step in conducting a Quantitative Phenomenology with Raven’s Eye is to get a sense of the whole. This step consists of identifying overrepresented gists and the geists that may potentially influence their expression.
2.1 Identify overrepresented gists. Several overrepresented1 gists2 are present in the natural language data set. Table 1 presents the top 25 most proportional words that are overrepresented at least 4 or more times in the word pool formed by responses to Question 1, while Table 2 depicts the same for Question 2.
In Table 1, the words, we, our, and us can be combined to form one gist, which would be labeled we. Likewise, the words happy and happiness can be combined to form a gist labeled happy. In Table 2, the words, I, my, and me can be combined to form a gist labeled I, while the words, live and living can be combined to form the gist live, and the words experience and experiences can be combined to form the gist experience.
In Table 1, the words, we, our, and us can be combined to form one gist, which would be labeled we. Likewise, the words happy and happiness can be combined to form a gist labeled happy. In Table 2, the words, I, my, and me can be combined to form a gist labeled I, while the words, live and living can be combined to form the gist live, and the words experience and experiences can be combined to form the gist experience.
Table 1. Top 25 words that are overrepresented at least 4 or more times for Question 1:…what is the meaning of life?
| Word | # Sample | % Sample | % Corpus | Over- representation |
| life | 733 | 4.146 | 0.045 | 92.133 |
meaning | 363 | 2.053 | 0.008 | 256.625 |
we | 324 | 1.833 | 0.38 | 4.824 |
our | 126 | 0.713 | 0.122 | 5.844 |
your | 116 | 0.656 | 0.104 | 6.308 |
others | 105 | 0.594 | 0.021 | 28.286 |
live | 104 | 0.588 | 0.021 | 28 |
love | 103 | 0.583 | 0.018 | 32.389 |
make | 78 | 0.441 | 0.067 | 6.582 |
god | 75 | 0.424 | 0.01 | 42.4 |
world | 75 | 0.424 | 0.047 | 9.021 |
things | 71 | 0.402 | 0.061 | 6.59 |
believe | 71 | 0.402 | 0.02 | 20.1 |
good | 69 | 0.39 | 0.094 | 4.149 |
should | 68 | 0.385 | 0.077 | 5 |
purpose | 63 | 0.356 | 0.007 | 50.857 |
happy | 59 | 0.334 | 0.007 | 47.714 |
us | 57 | 0.322 | 0.054 | 5.963 |
family | 54 | 0.305 | 0.042 | 7.262 |
happiness | 52 | 0.294 | 0.001 | 294 |
enjoy | 49 | 0.277 | 0.012 | 23.083 |
help | 49 | 0.277 | 0.029 | 9.552 |
learn | 45 | 0.255 | 0.009 | 28.333 |
person | 44 | 0.249 | 0.019 | 13.105 |
find | 42 | 0.238 | 0.039 | 6.103 |
Table 2. Top 25 words that are overrepresented at least 4 or more times for Question 2: tell us… how it is that you came to your perspective on the meaning of life.
| Word | # Sample | % Sample | % Corpus | Over- representation |
| I | 601 | 5.15 | 1.056 | 4.877 |
life | 296 | 2.536 | 0.045 | 56.356 |
my | 256 | 2.193 | 0.168 | 13.054 |
me | 109 | 0.934 | 0.085 | 10.988 |
meaning | 84 | 0.72 | 0.008 | 90 |
things | 68 | 0.583 | 0.061 | 9.557 |
came | 67 | 0.574 | 0.022 | 26.091 |
perspective | 56 | 0.48 | 0.004 | 120 |
through | 51 | 0.437 | 0.065 | 6.723 |
others | 47 | 0.403 | 0.021 | 19.19 |
god | 43 | 0.368 | 0.01 | 36.8 |
am | 41 | 0.351 | 0.02 | 17.55 |
believe | 36 | 0.308 | 0.02 | 15.4 |
family | 35 | 0.3 | 0.042 | 7.143 |
live | 34 | 0.291 | 0.021 | 13.857 |
world | 34 | 0.291 | 0.047 | 6.191 |
living | 34 | 0.291 | 0.014 | 20.786 |
I’ve | 30 | 0.257 | 0.052 | 4.942 |
experience | 28 | 0.24 | 0.013 | 18.462 |
experiences | 28 | 0.24 | 0.003 | 80 |
feel | 28 | 0.24 | 0.024 | 10 |
love | 27 | 0.231 | 0.018 | 12.833 |
happy | 26 | 0.223 | 0.007 | 31.857 |
always | 24 | 0.206 | 0.038 | 5.421 |
thought | 23 | 0.197 | 0.03 | 6.567 |
Table 1. Top 25 words that are overrepresented at least 4 or more times for Question 1:…what is the meaning of life?
| Word | # Sample | % Sample | % Corpus | Overrepresentation |
|---|---|---|---|---|
| life | 733 | 4.146 | .045 | 92.133 |
| meaning | 363 | 2.053 | .008 | 256.625 |
| we | 324 | 1.833 | .38 | 4.824 |
| our | 126 | .713 | .122 | 5.844 |
| your | 116 | .656 | .104 | 6.308 |
| others | 105 | .594 | .021 | 28.286 |
| live | 104 | .588 | .021 | 28 |
| love | 103 | .583 | .018 | 32.389 |
| make | 78 | .441 | .067 | 6.582 |
| god | 75 | .424 | .01 | 42.4 |
| world | 75 | .424 | .047 | 9.021 |
| things | 71 | .402 | .061 | 6.59 |
| believe | 71 | .402 | .02 | 20.1 |
| good | 69 | .39 | .094 | 4.149 |
| should | 68 | .385 | .077 | 5 |
| purpose | 63 | .356 | .007 | 50.857 |
| happy | 59 | .334 | .007 | 47.714 |
| us | 57 | .322 | .054 | 5.963 |
| family | 54 | .305 | .042 | 7.262 |
| happiness | 52 | .294 | .001 | 294 |
| enjoy | 49 | .277 | .012 | 23.083 |
| help | 49 | .277 | .029 | 9.552 |
| learn | 45 | .255 | .009 | 28.333 |
| person | 44 | .249 | .019 | 13.105 |
| find | 42 | .238 | .039 | 6.103 |
Table 2. Top 25 words that are overrepresented at least 4 or more times for Question 2: tell us… how it is that you came to your perspective on the meaning of life.
| Word | # Sample | % Sample | % Corpus | Overrepresentation |
|---|---|---|---|---|
| I | 601 | 5.15 | 1.056 | 4.877 |
| life | 296 | 2.536 | .045 | 56.356 |
| my | 256 | 2.193 | .168 | 13.054 |
| me | 109 | .934 | .085 | 10.988 |
| meaning | 84 | .72 | .008 | 90 |
| things | 68 | .583 | .061 | 9.557 |
| came | 67 | .574 | .022 | 26.091 |
| perspective | 56 | .48 | .004 | 120 |
| through | 51 | .437 | .065 | 6.723 |
| others | 47 | .403 | .021 | 19.19 |
| god | 43 | .368 | .01 | 36.8 |
| am | 41 | .351 | .02 | 17.55 |
| believe | 36 | .308 | .02 | 15.4 |
| family | 35 | .3 | .042 | 7.143 |
| live | 34 | .291 | .021 | 13.857 |
| world | 34 | .291 | .047 | 6.191 |
| living | 34 | .291 | .014 | 20.786 |
| I’ve | 30 | .257 | .052 | 4.942 |
| experience | 28 | .24 | .013 | 18.462 |
| experiences | 28 | .24 | .003 | 80 |
| feel | 28 | .24 | .024 | 10 |
| love | 27 | .231 | .018 | 12.833 |
| happy | 26 | .223 | .007 | 31.857 |
| always | 24 | .206 | .038 | 5.421 |
| thought | 23 | .197 | .03 | 6.567 |
2.2 Identify potentially influential geists. To identify potentially influential geists, we first examine the metadata derived from the natural language pool by Raven’s Eye. We then consider specific influences related to the zeitgeist, ortgeist, and kulturgeist, which contextualize our results.
2.2.1 Metadata. We reported on the metadata arising from consideration of the acquired natural language pool in its entirety during step 1.6.2. In this step, we inspect for substantial variation in this data according to identifiable variables. Because the natural language pool was acquired across two distinct questions, in this section we divide the report and inspection of their results accordingly.
Question 1: Over the course of a short paragraph (i.e., 3-5 sentences), please tell us in your own words: what is the meaning of life? The total response pool for this question was comprised of 17678 words, which were spread across 1214 sentences. The average sentence length was 14.56 words. Given that the average response contained 51.09 words, the typical participant used about 3.5 sentences (3.51) to answer the question. The Flesch Reading Ease Score for the pool was 75.75, while the Flesch-Kincaid Grade Level was 6.31.
When the metadata for Question 1 are compared across the classes of variables acquired, we find no substantial variation (see Table 3). However, we do note that there is a tendency for participants from India to express statements that are somewhat less complex than those from the United States, and that women tend to be somewhat more verbose than men.
When the metadata for Question 1 are compared across the classes of variables acquired, we find no substantial variation (see Table 3). However, we do note that there is a tendency for participants from India to express statements that are somewhat less complex than those from the United States, and that women tend to be somewhat more verbose than men.
Table 3. Comparison of metadata across variables for Question 1:…what is the meaning of life?
Female | Male | India | U.S. | |
| Word Count | 10710 | 6968 | 3193 | 14485 |
Sentence Count | 729 | 486 | 264 | 951 |
Sentence Length | 14.69 | 14.33 | 12.09 | 15.23 |
Average Response Length | 53.02 | 48.39 | 38.47 | 55.08 |
Average Sentences per Response | 3.61 | 3.38 | 3.18 | 3.62 |
Flesch Reading Ease | 77.04 | 73.8 | 79.14 | 74.87 |
Flesch-Kincaid Grade Level | 6.16 | 6.53 | 5.22 | 6.6 |
| Variable | Word Count | Sentence Count | Sentence Length | Average Response Length | Average Sentences per Response | Flesch Reading Ease Score | Flesch-Kincaid Grade Level |
|---|---|---|---|---|---|---|---|
| Female | 10710 | 729 | 14.69 | 53.02 | 3.61 | 77.04 | 6.16 |
| Male | 6968 | 486 | 14.33 | 48.39 | 3.38 | 73.8 | 6.53 |
| India | 3193 | 264 | 12.09 | 38.47 | 3.18 | 79.14 | 5.22 |
| U.S. | 14485 | 951 | 15.23 | 55.08 | 3.62 | 74.87 | 6.6 |
Question 2: Over the course of a sentence or two, please tell us in your own words how it is that you came to your perspective on the meaning of life. The total response pool for this question was comprised of 11671 words, which were spread across 749 sentences. The average sentence length was 15.58 words. Given that the average response contained 33.73 words, the typical participant used a little over two sentences (2.16) to answer the question. The Flesch Reading Ease Score for the pool was 72.31, while the Flesch-Kincaid Grade Level was 7.04.
When the metadata for Question 2 are compared across the classes of variables acquired, we find no substantial variation (see Table 4). However, and as with Question 1, we do note that there is a tendency for participants from India to express statements that are somewhat less complex than those from the United States, and that women tend to be somewhat more verbose than men.
When the metadata for Question 2 are compared across the classes of variables acquired, we find no substantial variation (see Table 4). However, and as with Question 1, we do note that there is a tendency for participants from India to express statements that are somewhat less complex than those from the United States, and that women tend to be somewhat more verbose than men.
Table 4. Comparison of metadata across variables for Question 2:Tell us…how it is that you came to your perspective on the meaning of life.
Female | Male | India | U.S. | |
| Word Count | 7371 | 4300 | 1856 | 9815 |
Sentence Count | 465 | 285 | 147 | 603 |
Sentence Length | 15.85 | 15.08 | 12.63 | 16.28 |
Average Response Length | 36.49 | 29.86 | 38.47 | 37.32 |
Average Sentences per Response | 2.3 | 1.98 | 3.05 | 2.29 |
Flesch Reading Ease | 73.33 | 70.6 | 78.1 | 71.08 |
Flesch-Kincaid Grade Level | 6.97 | 7.16 | 5.5 | 7.39 |
| Variable | Word Count | Sentence Count | Sentence Length | Average Response Length | Average Sentences per Response | Flesch Reading Ease Score | Flesch-Kincaid Grade Level |
|---|---|---|---|---|---|---|---|
| Female | 7371 | 465 | 15.85 | 36.49 | 2.3 | 73.33 | 6.97 |
| Male | 4300 | 285 | 15.08 | 29.86 | 1.98 | 70.6 | 7.16 |
| India | 1856 | 147 | 12.63 | 38.47 | 3.05 | 78.1 | 5.5 |
| U.S. | 9815 | 603 | 16.28 | 37.32 | 2.29 | 71.08 | 7.39 |
2.2.2 Zeitgeist. Our data for this initial project on the meaning of life were acquired during the eight-day period from September 15th, 2015 to September 22nd, 2015 (inclusive). The pattern of submissions during this period form a U-shape, with relatively greater frequency of submission per hour in the first and last days of the period (likely due to the way in which the lists of available surveys/tasks can be sorted in Amazon Mechanical Turk). More detailed information about the influence of time on the gists and themes in the data will be presented in subsequent analyses, when we have acquired more public responses across a greater duration of time.
2.2.3 Ortgeist. Our data for this initial project on the meaning of life were acquired from participants currently residing in either India or the United States. Given that the survey was delivered online, we cannot assume details of the immediate environment in which the survey was completed, other than to note that a computer, tablet, or cellphone was likely present in the immediate environment in order to enable completion of the survey. More detailed information about the influence of spaces and places on the gists and themes in the data will be presented in subsequent analyses, when we have acquired more public responses.
2.2.4 Kulturgeist. Our data for this initial project on the meaning of life were acquired from participants currently residing in either India or the United States. Given that the survey and its responses were in English, some familiarity with written English was required to understand and complete the survey. Though English is a lingua franca in India, it is likely that substantially more Indians than Americans write and speak English as a second language. The relative difference in language complexity and verbosity found in responses between participants in India and the US likely reflects this differential rate in language centrality/acquisition. More detailed information about the influence of culture on the gists and themes in the data will be presented in subsequent analyses, when we have acquired more public responses.
3. Constitute parts by identifying meaning units.
The third step in performing a Quantitative Phenomenology with Raven’s Eye is to constitute the parts of your natural language data by identifying the units of meaning contained within it.
3.1 Consider subdividing or combining portions of the natural language sample. Our natural language data were acquired via two distinct questions. When getting a sense of the whole, it becomes apparent that the responses from a majority of respondents to both questions contain two elements: (1) a topical introductory sentence that repeats portions of the question stem, and then states the main idea of the response; and (2) 2-3 sentences that generally elaborate on the main idea in the first sentence, while sometimes providing additionally associated concepts or ideas.
Given that this is an initial analysis, we continue to divide meaning units by their most overt form: each response to a question is considered one complete unit of meaning. The sample continues, therefore, to be divided into two main parts, in which each correspond to the two questions asked of the participants. If desired or needed for increased specificity, in subsequent analyses we might consider separating the first sentence in each response from the other sentences in the response, and analyzing these as separate meaning units.
Given that this is an initial analysis, we continue to divide meaning units by their most overt form: each response to a question is considered one complete unit of meaning. The sample continues, therefore, to be divided into two main parts, in which each correspond to the two questions asked of the participants. If desired or needed for increased specificity, in subsequent analyses we might consider separating the first sentence in each response from the other sentences in the response, and analyzing these as separate meaning units.
3.2 Consider response-based characteristics. As apparent in the tables presented previously during section 2.1, gists such as love, god, world, good, and happy are overrepresented in response to Question 1. Likewise, gists such as others, god, family, live, world, and experience are overrepresented in response to Question 2. Because we are presenting our initial results in this project at this time, we refrain from partitioning our meaning units according to these specific responses. However, in future studies when more participants are acquired, we may want to subdivide our meaning units according to one or more of these specific responses, and compare these units to those that include other responses (e.g., we might consider those that cite god in both questions, as compared to those that do not, or we might compare those that mention god versus those that mention the world, etc.).
3.3 Consider states of geists and other variables. We started our project interested in whether or not people from India cite different gists or concepts than people from the United States, whether or not females cite different gists or concepts than males, and whether or not age or cohort appears to lead to differential gist or concept usage. We do, therefore, partition our data according to these variables. In that which follows, we report when such partitions result in meaningful variation in content.
4. Transform data into revelatory statements.
As described in our Methods section, the fourth step in performing a Quantitative Phenomenology with Raven’s Eye is to transform data into revelatory statements.
4.1 Construct concepts by elaborating overrepresented gists. In Raven’s Eye, a concept is defined as an elaborated cluster of synonymous or otherwise functionally equivalent gists. To elaborate on overrepresented gists, then, one combines those gists that are both synonymous with each other, and function similarly, into one concept. The label for this concept is derived from the most proportional overrepresented gist within its cluster.
With respect to our current project, when overrepresented gists are elaborated, several key concepts emerge for each question. Given that this is an initial demonstration of how to conduct a Quantitative Phenomenology with Raven’s Eye on this topic, we provide examples for the top ten concepts for each question.
With respect to our current project, when overrepresented gists are elaborated, several key concepts emerge for each question. Given that this is an initial demonstration of how to conduct a Quantitative Phenomenology with Raven’s Eye on this topic, we provide examples for the top ten concepts for each question.
Question 1: Over the course of a short paragraph (i.e., 3-5 sentences), please tell us in your own words: what is the meaning of life?
Concept 1: Life.
gists: life, lifelong, lifestyle, lifetime, livelihood, existence
Concept 6: Live.
gists: live, livable, alive
Concept 5: Others.
gists: others, people, person, human being
Concept 10: World.
gists: world, Earth, planet, universe, creation
Concept 2: Meaning.
gists: meaning, mean, meaningful, meaningless
Concept 7: Love.
gists: love, care
Concept 4: Your.
gists: your, yourself, you, you’re
Concept 9: God.
gists: god, creator, maker, almighty, Jehovah, Jesus, lord
Concept 3: We.
gists: we, we’re, our, us, ourself
Concept 8: Make.
gists: make, create
Question 2: Over the course of a sentence or two, please tell us in your own words how it is that you came to your perspective on the meaning of life.
Concept 1: I.
gists: I, myself
Concept 6: Perspective.
gists: perspective, conclusion, opinion
Concept 5: Came.
gists: came, learned, realized
Concept 10: Am.
gists: am, have, was
Concept 2: Life.
gists: life
Concept 7: Through.
gists: through, from, by
Concept 4: Things.
gists: things, experiences
Concept 9: God.
gists: god, Jesus, lord, Krishna, almighty
Concept 3: Meaning.
gists: meaning, meant, meaningful, meaningless
Concept 8: Others.
gists: others, people, person, human being
4.2 Associate overrepresented concepts. To associate overrepresented concepts, we examine the relations between their respective gists, as these occur in the context of the original natural language response. In 3.1 we noted that most responses took the form of a topical introductory statement that repeats a portion of the question’s stem, and then provides a main idea in response to that question. The remainder of each response then typically elaborates on this main idea. In this section of this demonstration, we show how this pattern emerges from the most proportional and overrepresented gists and concepts for each question.
When associating gists and concepts, we examine their general associations, as well as their ordered relations and contingencies. Doing so describes the manner in which these gists and concepts are related in the natural language data (and, as, an extension, in the expressed thoughts of the person or people supplying the natural language data). It also serves as the first stage in constructing statements that convey the essential meaning in the data, via the words of the participants themselves.
Question 1: Over the course of a short paragraph (i.e., 3-5 sentences), please tell us in your own words: what is the meaning of life?
Concept 1: Life.
Generally associated gists and overrepresented concepts. Video 1 demonstrates how a general sense of the relations between the gists and concepts in a natural language sample is provided by examining the 5 words surrounding a target word. Here, the target word is life, which is the most frequent gist of the eponymously named concept. As can be seen in Video 1, the top five most proportionally represented gists surrounding the overrepresented gist life are: is, the, of, to, and meaning. The top five overrepresented concepts surrounding the overrepresented gist life are: meaning, life, live, we, your (via the gists you and your).
Ordered relations and contingencies. As further demonstrated in Video 1, the ordered relations and contingencies between gists and concepts are identified by successively narrowing the Word Association analysis from the 5 words preceding the target word to 1 word preceding the target word, and then repeating this procedure for the words that follow the target word.
Video 1. The procedures involved in step 4.2, with respect to the first sufficiently overrepresented gist (word) from Question 1: life.
Gists and overrepresented concepts preceding the target word: The top five most proportionally represented gists generally preceding the gist life are: of, the, meaning, to, and in. The most frequently occurring gist directly preceding the gist life is of (directly preceding life in approximately 41% of instances), followed by in, your, a, and to.
The top five most frequent and overrepresented concepts generally preceding the gist life are, in order: meaning, your, live, believe, and we. Successively narrowing the Word Association analysis reveals that approximately 40% of instances of the gist life in a sentence are preceded within two words by the overrepresented concept meaning3. Overrepresented concepts directly preceding the gist life include: your, live, we (via the gist our), and enjoy.
Gists and overrepresented concepts following the target word: The top five most proportionally represented gists generally following the gist life are: is, to, and, a, and the. The most frequently occurring gists directly following the gist life are: is (accounting for 47% of instances), to, and, in, and means.
The top five most frequent and overrepresented concepts generally following the gist life are, in order: we, life, your (via the gist you), meaning, and live. Overrepresented concepts directly following the gist life include: meaning (via the gist means), we, should, your (via the gist you), and consists.
Question 2: Over the course of a sentence or two, please tell us in your own words how it is that you came to your perspective on the meaning of life.
Concept 1: I.
Generally associated gists and overrepresented concepts. The top five most proportionally represented gists surrounding the overrepresented gist I are: to, I, and, my, and the. The top five overrepresented concepts surrounding the overrepresented gist I are: I, life, have, came, and perspective.
Ordered relations and contingencies. As noted previously, the ordered relations and contingencies between gists and concepts are identified by successively narrowing the Word Association analysis from the 5 words preceding the target word to 1 word preceding the target word, and then repeating this procedure for the words that follow the target word.
Gists and overrepresented concepts preceding the target word: The top five most proportionally represented gists generally preceding the gist I are: and, I, when, the, and that. The most frequently occurring gists directly preceding the gist I are: when, and, that, what, and but.
The top five most frequent and overrepresented concepts generally preceding the gist I are, in order: I (via the gists I and my), life, am (via the gist was), way, and feel. Overrepresented concepts directly preceding the gist I include: life, way, thinking (via the gist think), older, and things.
Gists and overrepresented concepts following the target word: The top five most proportionally represented gists generally following the gist I are: to, and, my, a, and have. The most frequently occurring gists directly following the gist I are: have, came, was, am, and feel.
The top five most frequent and overrepresented concepts generally following the gist I are, in order: I (via the gists my and I), am (via the gists have and am), came, life, and perspective. Overrepresented concepts directly following the gist I include: have via the gists have, am, and was) and came at nearly equal rates, followed by feel, believe, and thinking (via the gist think).
4.3 Construct revelatory statements based on the associations between overrepresented concepts. The concepts expressed in the responses can be associated to form several revelatory statements.
Question 1: Over the course of a short paragraph (i.e., 3-5 sentences), please tell us in your own words: what is the meaning of life?
Revelatory statements for concept 1: Life.
As may be readily apparent from section 4.2, the phrase, the meaning of life is [to] readily emerges from the data. This phrase forms the beginning of a highly popular topical introductory statement utilized among responses to Question 1: …what is the meaning of life?
Statements derived from associated concepts preceding the gist.
the meaning of…
Statements derived from associated concepts following the gist.
… is…
… is to…
… is to…
Question 2: Over the course of a sentence or two, please tell us in your own words how it is that you came to your perspective on the meaning of life.
Revelatory statements for concept 1: I.
Statements derived from associated concepts preceding the gist.
think…
Statements derived from associated concepts following the gist.
… have…
… came to my perspective…
… came to my perspective…
5. Identify essential structure.
Notes.
1 As noted in Step 2.1 of performing a Quantitative Phenomenology with Raven’s Eye, the Overrepresentation of a term is defined as the quotient produced when the proportion of the term in the sample is divided by the proportion of that same term in the background comparison corpus. Using the columns in Tables 1 and 2, this formula can be written as: %Sample / %Corpus = Overrepresentation. Because it is a quotient thusly calculated, a term’s Overrepresentation is also the factor by which the %Corpus must be multiplied to arrive at a proportion similar to its use in the sample. It represents, therefore, the number of times more proportional a given word is found in a particular sample, when compared to its rate of use in the background corpus.
2 As noted in Step 2.1 of performing a Quantitative Phenomenology with Raven’s Eye, a gist represents all of a given word’s applicable inflections found in the sample, but it assumes the label of the word’s most proportional inflection.
3 We limit the discussion in this section to illustrating how to associate the concept life. However, when we inspect the overrepresented concept meaning, (i.e., selecting the gist meaning in the main table, and then use the Word Association feature to inspect the two words that follow it in a sentence) reveals that approximately 80% of instances of the gist meaning are followed within two words by the concept life.
2 As noted in Step 2.1 of performing a Quantitative Phenomenology with Raven’s Eye, a gist represents all of a given word’s applicable inflections found in the sample, but it assumes the label of the word’s most proportional inflection.
3 We limit the discussion in this section to illustrating how to associate the concept life. However, when we inspect the overrepresented concept meaning, (i.e., selecting the gist meaning in the main table, and then use the Word Association feature to inspect the two words that follow it in a sentence) reveals that approximately 80% of instances of the gist meaning are followed within two words by the concept life.